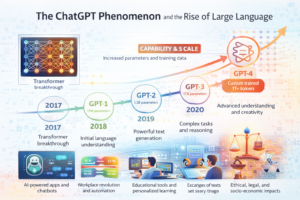
In November 2022, OpenAI released ChatGPT, sparking an AI revolution that captured global attention. Within five days, it reached 1 million users, and by January 2024, it had become one of the fastest-growing applications in history. But ChatGPT is just one example of a broader revolution in large language models (LLMs) that are transforming how we interact with technology.
What Are Large Language Models?
Large Language Models are AI systems trained on massive amounts of text data to understand and generate human-like language. These models contain billions or even trillions of parameters and can perform a wide range of tasks including writing, coding, analysis, translation, and creative work—all through natural conversation.
Key Characteristics of Modern LLMs
- Scale: Billions to trillions of parameters
- Pre-training: Trained on vast amounts of internet text
- Few-Shot Learning: Adapt to new tasks with minimal examples
- Emergent Abilities: Capabilities that appear at certain model sizes
- Context Understanding: Comprehend and maintain conversational context
Evolution of LLMs: A Timeline
- 2018: BERT revolutionizes NLP with bidirectional training
- 2019: GPT-2 shows impressive text generation (1.5B parameters)
- 2020: GPT-3 debuts with 175B parameters, demonstrating few-shot learning
- 2022: ChatGPT launches, making LLMs accessible to everyone
- 2023: GPT-4, Claude 2, Gemini, and open-source models proliferate
- 2024: Multimodal models, longer contexts, and specialized LLMs emerge
Leading LLMs in 2024
OpenAI GPT-4 and GPT-4 Turbo
The most advanced model from OpenAI, featuring multimodal capabilities (text and images), 128K token context window, and state-of-the-art performance across numerous benchmarks. Powers ChatGPT Plus and Enterprise.
Anthropic Claude 3 (Opus, Sonnet, Haiku)
Known for longer context windows (200K tokens), strong reasoning abilities, and constitutional AI training focused on helpfulness and harmlessness. Particularly excels at analysis and nuanced tasks.
Google Gemini Ultra and Pro
Google’s multimodal models trained from scratch to understand text, images, audio, and video. Deeply integrated with Google services and search capabilities.
Open-Source Models
- Meta LLaMA 3: High-performance open model available in various sizes
- Mistral and Mixtral: Efficient models using Mixture of Experts
- Falcon: Powerful models trained on refined datasets
- MPT and StableLM: Commercial-friendly open alternatives
How LLMs Are Trained
Phase 1: Pre-training
Models learn language patterns by predicting the next word in billions of text examples from books, websites, and other sources. This unsupervised learning phase creates a foundational understanding of language.
Phase 2: Instruction Fine-Tuning
Models are trained on specific instruction-following examples to better understand and respond to user requests.
Phase 3: Reinforcement Learning from Human Feedback (RLHF)
Human trainers rank model outputs, and the model learns to produce responses that align with human preferences and values.
Real-World Applications
Content Creation and Writing
- Blog posts, articles, and marketing copy
- Creative writing and storytelling
- Email drafting and communication
- Social media content generation
Programming and Development
- Code generation and completion
- Debugging and error resolution
- Documentation writing
- API integration assistance
Business and Productivity
- Data analysis and insights
- Report generation
- Meeting summarization
- Customer support automation
Education and Learning
- Personalized tutoring
- Concept explanation
- Language learning
- Study material generation
Capabilities and Limitations
Strengths
- Versatility: Handle diverse tasks without specific training
- Context Awareness: Understand and maintain conversation flow
- Reasoning: Break down complex problems step-by-step
- Creativity: Generate novel ideas and content
- Language Understanding: Work across 100+ languages
Limitations
- Hallucinations: Sometimes generate incorrect or fabricated information
- Knowledge Cutoff: Training data has a specific end date
- No Real-Time Access: Cannot browse the web (unless specifically enabled)
- Math Limitations: May struggle with complex calculations
- Inconsistency: Responses can vary across similar queries
Prompt Engineering: Getting the Best Results
Best Practices
- Be Specific: Provide clear, detailed instructions
- Give Context: Include relevant background information
- Use Examples: Show the format or style you want
- Break Down Tasks: Divide complex requests into steps
- Iterate: Refine prompts based on outputs
- Specify Format: Request output in specific structures (JSON, markdown, etc.)
Advanced Techniques
- Chain-of-Thought: Ask the model to explain its reasoning
- Role Assignment: “You are an expert in…”
- Few-Shot Learning: Provide examples in your prompt
- System Messages: Set consistent behavior patterns
Ethical Considerations and Challenges
Bias and Fairness
LLMs can reflect biases present in their training data. Developers work to mitigate these through careful dataset curation and alignment techniques.
Misinformation
The ability to generate convincing text raises concerns about deepfakes, fake news, and academic dishonesty. Watermarking and detection tools are being developed.
Privacy and Data Security
Questions about training data sources and user conversation privacy remain important considerations.
Employment Impact
LLMs are transforming many professions, raising questions about job displacement and the need for reskilling.
The Future of LLMs
Emerging Trends
- Multimodal Capabilities: Understanding images, audio, video natively
- Extended Context: Processing millions of tokens at once
- Real-Time Learning: Models that update knowledge continuously
- Specialized Models: Domain-specific LLMs for medicine, law, finance
- Edge Deployment: Running powerful models on consumer devices
- Agent Systems: LLMs that can take actions and use tools
Integration Everywhere
LLMs are being embedded into:
- Office productivity tools (Microsoft 365 Copilot, Google Workspace)
- Development environments (GitHub Copilot, Cursor)
- Search engines (Bing Chat, Google SGE)
- Customer service platforms
- Creative tools (Adobe Firefly, Canva)
Getting Started with LLMs
For Users
- Start with ChatGPT, Claude, or Gemini
- Experiment with different prompting techniques
- Join communities to learn best practices
- Use LLMs to enhance your productivity
For Developers
- Explore APIs (OpenAI, Anthropic, Cohere)
- Use Hugging Face for open-source models
- Learn LangChain for building LLM applications
- Experiment with fine-tuning and RAG (Retrieval-Augmented Generation)
Conclusion
Large Language Models represent one of the most significant technological breakthroughs of our time. ChatGPT brought AI to the mainstream, but it’s just the beginning. As LLMs become more capable, efficient, and accessible, they will continue transforming how we work, learn, create, and communicate.
Understanding LLMs is no longer optional for tech professionals—it’s essential. Whether you’re a developer building the next generation of AI applications, a business leader exploring AI adoption, or simply someone curious about the technology shaping our future, now is the time to engage with Large Language Models and explore their transformative potential.
Continue Learning: Related Articles
ChatGPT for Enterprise: Implementation Strategy, Security Considerations, and ROI Analysis
ChatGPT for Enterprise: Implementation Strategy, Security Considerations, and ROI Analysis Meta Description: Implement …
📖 13 min read
Building Effective AI Recommendation Systems: Collaborative Filtering, Content-Based, and Hybrid Approaches
Building Effective AI Recommendation Systems: Maximizing User Engagement and Revenue Recommendation systems are among t…
📖 8 min read
Learning Path: AI Tools Mastery
Learning Path: AI tools Mastery Duration: 6-8 weeks | Weekly Commitment: 15-20 hours | Prerequisites: Basic Python knowl…
📖 3 min read
Build an AI News Summarizer: Complete Python Tutorial for Automated Content Digests
Introduction to AI News Summarization In an era of information overload, AI-powered news summarization has become essen…
📖 17 min read
💡 Explore 80+ AI implementation guides on Harshith.org