The Emergence of Large Language Models
Large Language Models (LLMs) have revolutionized artificial intelligence, transforming how machines understand and generate human language. Models like GPT-4, Claude, and others have demonstrated unprecedented capabilities in language understanding, reasoning, and creative task execution. Understanding these systems requires exploring their architecture, training methodology, capabilities, and implications.
What Are Large Language Models?
Learn more: LLM fundamentals
Learn more: NLP
Large Language Models are neural networks trained on vast amounts of text data from the internet, books, and other sources. Unlike traditional rule-based language processing systems, LLMs learn patterns in language through statistical analysis of their training data. The “large” in LLM refers both to the enormous amount of training data and the massive number of parameters (billions to hundreds of billions) that make up these models.
The Transformer Architecture
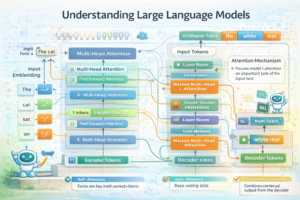
At the heart of modern LLMs lies the Transformer architecture, introduced by Vaswani et al. in 2017. This architecture uses attention mechanisms to process information, allowing the model to focus on different parts of the input data simultaneously. The Transformer’s key innovation is self-attention, which enables the model to weigh the importance of different words in understanding the meaning of each word in a sequence.
The attention mechanism works by creating three representations of each word: queries, keys, and values. The attention weights are calculated based on the similarity between queries and keys, determining how much each word should influence the final representation. This mechanism allows transformers to capture long-range dependencies and understand complex relationships between words in a text.
Training and Fine-Tuning Process
Pre-training: LLMs begin with unsupervised pre-training on massive text corpora. During this phase, the model learns to predict the next word given previous words (causal language modeling) or predict masked words in sentences (masked language modeling). This process forces the model to learn meaningful representations of language.
Fine-tuning: After pre-training, models are often fine-tuned on more specific tasks using supervised learning. For instance, models can be fine-tuned to follow instructions, answer questions accurately, or engage in dialogue.
Reinforcement Learning from Human Feedback (RLHF): Modern LLMs are often further refined using RLHF, where human annotators rate model outputs, and the model is trained to align its behavior with human preferences. This process significantly improves the quality and safety of model outputs.
Capabilities of Large Language Models
Natural Language Understanding: LLMs can understand complex language nuances, context, and intent. They can perform tasks like sentiment analysis, text classification, and information extraction with minimal task-specific training.
Text Generation: These models can generate coherent, contextually appropriate text across various domains and styles. From creative writing to technical documentation, LLMs can produce high-quality text.
Question Answering: LLMs can answer questions about facts, concepts, and procedures by leveraging knowledge learned during training and reasoning capabilities.
Translation: Modern LLMs can translate between languages with impressive accuracy, preserving meaning and nuance across linguistic boundaries.
Code Generation: LLMs trained on code repositories can generate functional code, debug existing code, and explain programming concepts.
Reasoning and Problem-Solving: Advanced LLMs demonstrate reasoning capabilities, including multi-step problem-solving, logical inference, and mathematical computation.
Scaling Laws and Emergent Capabilities
One of the most fascinating discoveries in LLM research is the existence of scaling laws—patterns showing how model performance improves with scale (more parameters, more training data, more computation). As models scale up, they sometimes suddenly develop new capabilities that weren’t present in smaller models. These “emergent capabilities” include abilities like in-context learning and reasoning that appear to arise spontaneously as models reach sufficient scale.
Limitations and Challenges
Hallucinations: LLMs sometimes generate false or nonsensical information with confidence. This hallucination problem is particularly concerning in high-stakes applications like healthcare or law.
Knowledge Cutoff: Models trained on data up to a certain date lack knowledge of more recent events, limiting their usefulness for current applications.
Bias and Fairness: LLMs can perpetuate or amplify biases present in their training data, leading to unfair or discriminatory outputs.
Computational Cost: Training and running LLMs requires enormous computational resources, making them expensive to develop and deploy.
Interpretability: Understanding how and why LLMs make specific decisions remains a significant challenge, limiting their applicability in critical domains.
Applications and Industry Impact
LLMs are transforming numerous industries. In customer service, they power intelligent chatbots that handle complex inquiries. In healthcare, they assist in medical record analysis and treatment planning. Education is being transformed through personalized tutoring systems. Legal research and contract analysis are being revolutionized by LLM capabilities. Creative industries are exploring LLMs for content generation and ideation.
The Future of Large Language Models
The field continues to evolve rapidly. We’re seeing development of multimodal models that combine text with images and other data types. Techniques for reducing hallucinations and improving reliability are being refined. Methods for making models more interpretable and controllable are advancing. Future developments will likely include better integration with external knowledge sources and reasoning systems, more efficient architectures that reduce computational requirements, and improved safety measures.
LLMs represent a fundamental shift in how we approach artificial intelligence. As they continue to advance, understanding their capabilities and limitations becomes increasingly important for everyone from technologists to policymakers.
Continue Learning: Related Articles
Learning Path: Deep Learning Progression
Learning Path: Deep Learning Progression
Duration: 10-12 weeks | Weekly Commitment: 20-25 hours | Prerequisites: Python …
📖 3 min read
Transfer Learning: Leveraging Pre-trained Models for Faster AI Development
Introduction to Transfer Learning
Transfer learning has revolutionized the field of artificial intelligence by enabling …
📖 8 min read
Build an AI Content Moderator: Complete Python Tutorial for Text and Image Moderation
Introduction to AI Content Moderation
Content moderation is one of the most critical applications of AI in the modern i…
📖 12 min read
Natural Language Processing: The Evolution from Rules to Neural Networks
The Journey of Natural Language Processing
Natural Language Processing (NLP) has undergone a remarkable transformation …
📖 6 min read
💡 Explore 80+ AI implementation guides on Harshith.org