AI Model Compression: Deploying Powerful AI to Edge Devices and Mobile Platforms
Modern AI models, particularly deep neural networks, have achieved remarkable capabilities across vision, language, and other domains. However, these models often contain millions or billions of parameters, requiring significant computational resources and storage space. This creates a fundamental challenge: how can we deploy sophisticated AI capabilities to edge devices like smartphones, IoT sensors, and embedded systems with limited computational power, memory, and battery life?
AI model compression addresses this challenge, enabling deployment of powerful AI models to resource-constrained devices. This comprehensive guide explores model compression techniques, their applications, implementation strategies, and the tradeoffs involved.
Why Model Compression Matters
Edge Deployment: Many applications benefit from running AI locally on edge devices rather than sending data to cloud servers. Model compression makes this feasible for resource-constrained devices.
Privacy: Processing data locally on user devices rather than sending to cloud servers improves privacy and gives users more control over their data.
Latency: Local inference eliminates network round-trip time, enabling real-time applications like augmented reality and autonomous vehicles.
Cost Reduction: Running inference locally reduces cloud computing costs significantly, improving overall system economics.
Reliability: Systems that work locally don’t depend on network connectivity, making them more reliable in diverse environments.
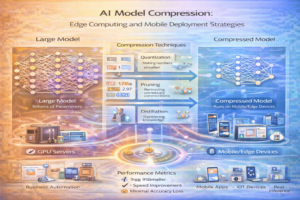
Model Compression Techniques
Quantization: Reducing the numerical precision of model weights and activations. Instead of 32-bit floating-point numbers, quantized models use 8-bit integers or even lower precision. This dramatically reduces model size and speeds up computation.
Pruning: Removing weights or neurons with small values, eliminating redundant components that don’t significantly contribute to model outputs. Pruning can reduce model size by 50-90% with minimal accuracy loss.
Knowledge Distillation: Training a smaller “student” model to mimic a larger “teacher” model. The student learns to reproduce the teacher’s behavior, often achieving comparable accuracy with significantly fewer parameters.
Matrix Factorization: Decomposing weight matrices into products of smaller matrices. This reduces the number of parameters while maintaining representational capability.
Architecture Search: Automatically discovering more efficient model architectures optimized for specific constraints. Neural Architecture Search (NAS) can find architectures that achieve better accuracy-efficiency tradeoffs than manually designed models.
Low-Rank Approximation: Representing high-dimensional weight matrices using lower-rank approximations, reducing computation and memory requirements.
Compression Strategies and Workflows
Step 1: Baseline Model: Start with a trained full-precision model. Understand its accuracy, latency, and size on your target device.
Step 2: Select Compression Techniques: Choose techniques appropriate for your constraints. For extreme compression, combine multiple techniques. For minimal accuracy loss, prioritize techniques that maintain model capacity.
Step 3: Post-Training Compression: Apply compression without retraining—quantization and pruning work well post-training. This is fastest but may sacrifice more accuracy.
Step 4: Fine-Tuning: After compression, fine-tune the compressed model on a small dataset to recover any lost accuracy. This typically recovers most of the accuracy loss from compression.
Step 5: Quantization-Aware Training: For maximum compression with minimum accuracy loss, retrain from scratch with quantization in the training loop. The model learns to be robust to quantization during training.
Step 6: Validation and Benchmarking: Thoroughly test the compressed model on diverse devices and conditions. Measure actual latency, power consumption, and accuracy in real deployment scenarios.
Real-World Implementation Examples
Mobile Computer Vision: MobileNets achieve impressive accuracy with small model sizes suitable for smartphones. By using depthwise separable convolutions and aggressive compression, they enable real-time mobile vision.
Voice Assistants: Speech recognition models are compressed to run locally on devices, enabling offline voice commands and improved privacy.
Object Detection: YOLO and SSD models are compressed for real-time detection on edge devices, enabling applications like security cameras and autonomous vehicles.
IoT Sensors: Machine learning models running on IoT devices enable predictive maintenance, anomaly detection, and edge analytics without cloud dependence.
Tools and Frameworks
TensorFlow Lite: Google’s framework for deploying TensorFlow models on mobile and edge devices. Includes quantization, pruning, and optimization tools.
PyTorch Mobile: Facebook’s solution for deploying PyTorch models to mobile devices with model compression and optimization.
ONNX: Open standard for model representation enabling cross-framework model deployment and optimization.
Neural Network Intelligence (NNI): Microsoft’s platform for neural architecture search and model compression.
TensorRT: NVIDIA’s inference optimizer for accelerating inference on GPU devices.
Tradeoffs and Considerations
Accuracy vs. Efficiency: Compression always involves tradeoffs. Aggressive compression reduces model size and latency but sacrifices accuracy. Finding the right balance for your application is crucial.
Development Time: Compressing models requires careful experimentation, benchmarking, and fine-tuning. This adds development time compared to simply using full-precision models.
Hardware Specificity: Optimal compression strategies often depend on specific hardware. A model optimized for one device may not perform well on another.
Maintenance: Compressed models may require re-compression after updates or retraining, adding maintenance complexity.
Best Practices for Model Compression
Profile First: Use profiling tools to identify performance bottlenecks. Focus compression efforts where they’ll have maximum impact.
Incremental Compression: Apply compression techniques incrementally, evaluating impact after each step.
Comprehensive Testing: Test on diverse devices, network conditions, and scenarios. Laboratory testing alone isn’t sufficient.
Monitor in Production: Deploy monitoring to track model accuracy and performance in real-world environments.
Plan for Updates: Design systems that can be updated with new model versions, supporting iterative improvements.
The Future of Edge AI
As edge devices become more powerful and compression techniques improve, we’ll see increasingly sophisticated AI running locally on devices. Future trends include on-device learning, where models improve over time by learning from local data, more specialized hardware accelerators optimized for AI inference, and more efficient model architectures designed from the ground up for edge deployment.
Conclusion
Model compression is essential for deploying sophisticated AI to resource-constrained devices. By combining quantization, pruning, knowledge distillation, and other techniques, organizations can achieve remarkable reductions in model size and latency while maintaining accuracy. As edge computing becomes increasingly important, mastery of model compression will be critical for building the next generation of AI applications.
Continue Learning: Related Articles
AI Monitoring and MLOps Platforms: Datadog vs New Relic vs Evidently vs MonitorDL
AI Monitoring and MLOps Platforms: Comparing Solutions for Model Performance and Drift Detection
Deploying machine lear…
📖 5 min read
AI Model Deployment Strategies: Production Best Practices & Cost Optimization
AI Model Deployment Strategies: Production Best Practices & Cost Optimization 2026
Meta Description: Master AI mode…
📖 10 min read
AI Ethics in Enterprise: Building Responsible AI Systems for Business
AI Ethics in Enterprise Applications: Building Responsible AI Systems for Business
The rapid advancement of artificial …
📖 7 min read
AI Code Review and Documentation Tools: GitHub Copilot vs CodeRabbit vs Codeium vs Blackbox
AI Code Review and Documentation Tools: Comparing Leading Solutions for Software Development
Artificial intelligence is…
📖 5 min read
💡 Explore 80+ AI implementation guides on Harshith.org